
前言
Google Gemma2/PaliGemma] Gemma2/PaliGemma 學習筆記,可以應用範圍這篇文章中我們有稍微介紹過如何在 LINE Bot 中如何使用 Gemma 這種稱為可以建置在本地端的 Local Model 。
本篇文章將更仔細的解釋相關用法,並且提供一些範例程式碼作為 LINE Bot 的範例。
Gemma/LLAMA 這一類的模型該如何部署
不論是 Gemma 還是 LLAMA 這一類可以部署在本地電腦(或是自己的雲端伺服器裡面的),在本文中都先暫且稱為 Local Model 。 他的基本 Prediction 的精準度,在於你提供的本地機器的算力。
筆電使用上 可以考慮使用 Ollama

Ollama 是一個跨平台很好使用 LLM 的本地端工具,可以在本地端的電腦去使用 Llama3, Phi 3, Mistral, Gemma2 等等本地端的模型。使用跟安裝也相當簡單,基本上現在只要是 M1 或是 M2 的 Mac Book 就可以很輕鬆地跑起相關的服務。
GCP / Vertex AI 上面要部署這些模型
可以透過 Vertex AI 的服務來部署
但是需要申請伺服器單位如列表
| Gemma / Gemma2 | PaliGemma |
|---|---|
| Machine type: ct5lp-hightpu-4t Accelerator type: TPU_V5_LITEPOD Accelerator count: 4 | - Machine type: g2-standard-16 - Accelerator type: NVIDIA_L4 - Accelerator count: 1 |
不過要注意這些單位需要申請,因為筆者還沒有申請下來本文將使用 Replicate 來示範。 (2024/07/19)
透過第三方模型託管服務 Replicate
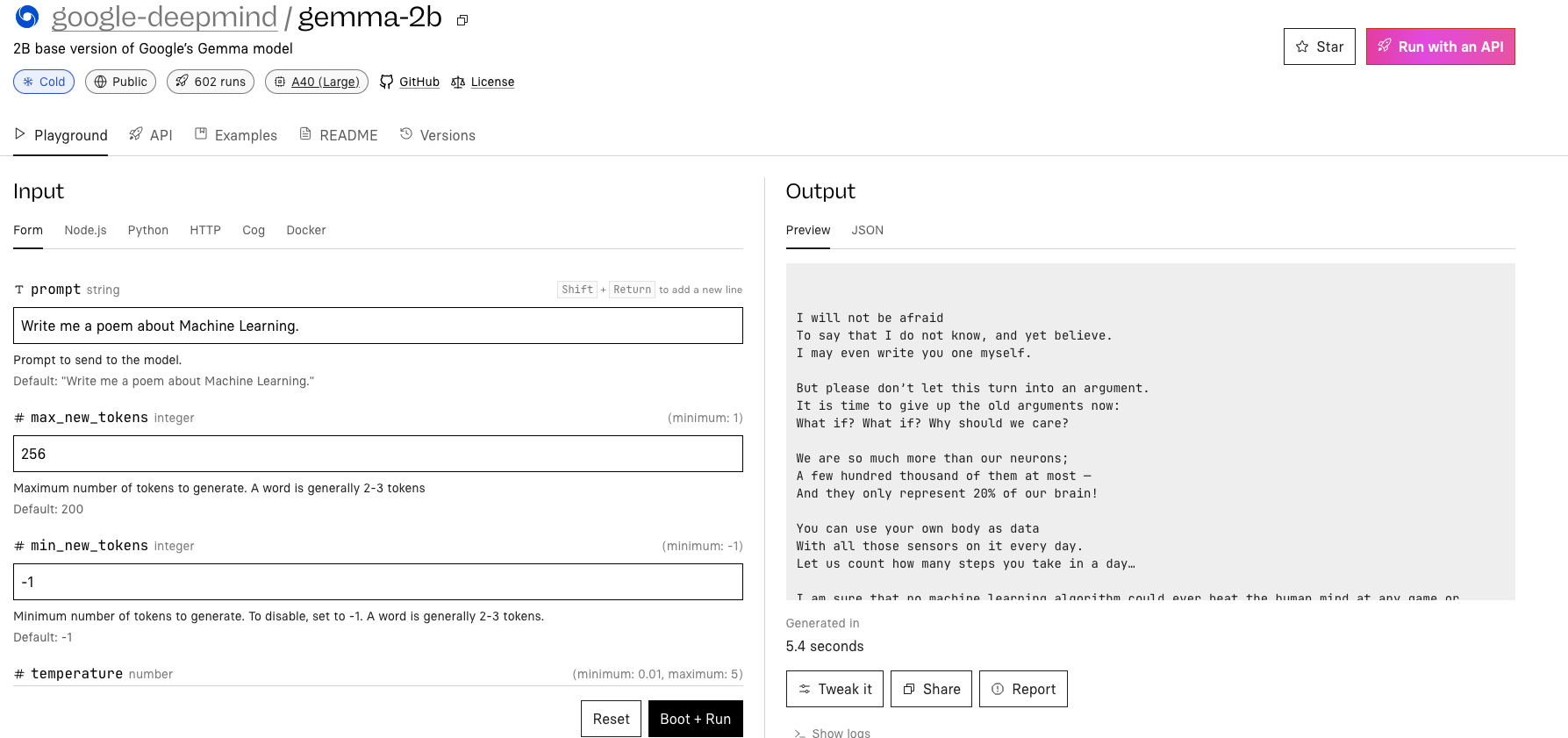
Replicate AI 是一間可以在雲端去測試這些本地端 Model 的網路服務提供商,可以在雲端上透過 UI 快速去了解並且測試。也可以 fint-tune 與部署自己本地端的模型在他們的服務上面。 本文的範例將這過他們的服務來架設。